

 probe used in heat treating steel")







In the sixth and final part on the impending factors of fatigue design, we illustrate the process of Weibull failure analysis. In engineering, we usually want to create a predictive model of component failure to guide us in our design intent or to do conformation testing to validate the integrity of the actual invention. Fatigue failure is investigated because most gearing and machine design components encounter dynamic stresses that are linear, rotational, or steady state or possess a varying duty cycle. Such components are intended to have a specific design life.
Knowing when a failure is likely to occur or being able to estimate a mean time to failure may be the most important analysis in mechanical and electrical engineering. Nothing could be more true in applications where the economics of failure are significant.
Dispersion or scatter of failure data about the mean is important in statistically predicting the fatigue limit of a component. Engineers can build rough models of design life by using classical methods of modified Goodman or Gerber life calculations with modifications to the pure material values published by the ASM or MPIF organizations. Additional calculations involving the Palmgren-Miner linear damage rule for multiple load variance may incorporate uncertainties that greatly affect the predictive life result. In order to verify the many assumptions that apply to the calculation model, actual design to failure testing from genuine or surrogate geometry is essential.
If variation of failure data is symmetrical about a mean value, then the probability density function (pdf) as characterized by a Gaussian or normal distribution will fit the data best. The function is represented by a bell-shaped curve as shown in Figure 1.

A random variable X is said to be normally distributed with mean μ and variance σ2, if its pdf is:
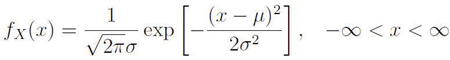
where: μ = population mean and σ2 is the population standard deviation squared and X = the individual data points.
When data conform to this type of distribution, 68.3 percent of the results will fall within ±1 standard deviation, 95.5 percent will fall within ±2 standard deviations and 99.7 percent will fall within ±3 standard deviations. When failure cannot be tolerated, six-sigma or ±6 standard deviations is often the standard. This represents a rate of 3.4 potential failures per million opportunities. In other words, six-sigma presents a 99.9997-percent success rate.
In statistical control, typical machine design data often exhibit outcomes in manufacturing parameters that are dispersed about the mean in a manner consistent with a normal distribution. Fatigue data, on the other hand, generally fits into a log-normal distribution. However, Weibull distributions are often preferred to log-normal due to the greater versatility of its distribution parameters. This is particularly true for fatigue and failure analysis. And mechanical failure and survival data usually fit and analyze best in a Weibull. The Weibull plot can vary in its shape and threshold to cover both normal and skewed curvature.
Consider the distribution plot in Figure 2. The scale is fixed at 10 while the shape of the curve varies.

The scale parameter is equal to the 63.2 percentile of the data under the curve. This means that when the Weibull X scale = 10, it represents 63.2 percent of the parts that are predicted to fail within the first 10 units.
The threshold parameter presents the earliest estimated time that a failure may occur. The threshold parameter locates the distribution along the X scale and shifts the distribution away from zero. Consider the effect of the Shape parameter on the probability density in Figure 2. This figure shows a two-parameter Weibull when the threshold parameter is set to zero. Note how the parameter changes the probability distribution (Figure 3).

The significance of the effect of the Shape B parameter or slope of the Weibull probability line is relative to the type of failure mode. Distributions with B < 1 show a significant percentage of infant or early-life failures. Distributions with B close to or equal to 1 will have more of a constant failure rate and could be interpreted as useful life with random failures. Weibull distributions with Shape B > 1 have a failure rate that increases with time and is often characterized as wear-out failure. For most mechanical designs, this is where the reliability of our components should be. Figure 4 shows that end-of-life failures have a much steeper slope, indicating that most failures increase dramatically at a specific lifetime. These three sections comprise the classic bathtub curve.

In general, for good machine component (i.e., mechanical design) when historical data is not available, simulations of the Shape function for reliability and confidence estimates fall between B = 2 and B 3.5, providing a goal for estimating the number of samples that need to be tested in order to build an accelerated or initial actual durability test plan. Specifying a confidence level also gives a quantitative measure of uncertainty. The greater the statistical confidence, the more conservative the test plan will become. Figure 5 shows how to calculate sample size.

In testing for the selected sample size, there can be no failures. If there is a failure, the test should be stopped. The reliability and confidence level should be calculated based on the number of samples tested at the number of cycles of the failed specimen. The opposite is also true. If there are no failures, test cycles can be continued to failure to determine the actual Weibull Shape function of component reliability. The new result can be recalculated to establish a greater reliability metric than what was originally tested for. Note: Be wary of small samples. There are statistics that can guide the technologist on optimum sample size and the power of the test, which are beyond the scope of this paper.
In automotive testing, the goal is often to verify that a component or system will not fail for the 10th percentile customer in 10 years or 150,000 miles. That is a 90-percent success rate. However, the best OEMs can and do ask for 1.5 to 2.0 times that requirement. For example, a vehicle transmission failure occurred at nine years and 80,000 miles. With my 10-year, 70,000-mile warranty, I was unhappy with the product. In examining the reason for failure (torque converter shaft fatigue), it was determined that an additional 3.0 mm or 0.118 inches of shaft diameter would have theoretically taken the minimum fatigue life for failure readily out to 150,000 to 250,000 miles. The cost of poor quality was simple, and this customer never bought from that OEM again. Simply put, the correct statistical simulation and design matters to your bottom line and your customers.
Motor Bracket Testing
The following data represent a motor bracket torque to failure test. The required design life is 200 percent of maximum application torque for 25,000 cycles of a varying duty cycle load. It is an accelerated test where 15 hours of testing represents two design lives or 20 years of normal operation. All brackets are tested to failure. The best fit distribution of the data turns out to be a Weibull plot, as expected, since this is failure data (Figure 6).

The analysis is done using a “least squares” failure time X on Y rank test. This calculation is chosen because we are using a fairly small sample size. The analysis declares a failure censor at sample 31 because there are only 30 samples tested, and all have failed. If we stopped the test before some of the samples failed, we could censor the survival of those samples and still be able to predict the mean application life of the bracket. We see that the Shape function is significantly greater than 3.50. This tells us that the failure is in the long-term wear-out portion of the bathtub curve. The Scale factor tells us that 62.3 percent of the failures in a population of these brackets will occur at 30.13 hours of accelerated sample testing. The dispersion of the mean line gives a standard deviation of 0.65 hours of variation. The mean and median are close together at 24.85 hours and is 1.65 times our 200-percent design life requirement. The two lines paralleling the mean failure line are the 95-percent confidence limits. From that data, we can say that the minimum 1-percent failure rate will be approximately 27.15 hours. Although not shown, a six-sigma percentile is also calculated, telling us that the minimum confidence limit for 3.4 failures per million opportunities is 22.7 hours or more than 1.5 times our 200-percent design life requirement. This is a robust design determined from our 30 samples.
Also, the Anderson Darling (AD) statistic at 0.562 measures how likely the data follow a particular distribution. The smaller the AD statistic, the better the fit. In failure or survival analysis, the AD statistic helps us to choose between the Weibull and log-normal distributions or to test whether data meets the assumption of normality for a comparative t-test. More sample testing would most likely shrink the 95-percent confident bands. Lastly, our probability plot tells us that the correlation is 0.994. This means that the 99.4 percent of all the failure data is described by the failure plot – a highly correlated result.
Another use for the Weibull distribution is in the discernment of capability. Usually, capability studies are done on manufacturing parameters to see whether a process is continuously capable of a specific parameter or specification. However, capability analysis can also be tuned to failure data describing the performance of the manufactured state of the component (Figure 7).

Because the distribution of data skews to the right and we know from the probability plot that the data best fit to a Weibull distribution rather than normal, we fit the capability analysis likewise. Note that in the table of percentiles, we calculated a six-sigma failure percentile at 3.4 ppm. According to that table, the lower and upper 95-percent confidence limits are 22.68 and 26.04 hours respectively. If we average maximum and minimum limits, the mean value becomes 24.32 hours. If we add the Standard Error, a statistical term that measures the accuracy with which a sample represents a population, we get (24.32 + 0.856) = 25.18 or approximately 25.2 hours of survival capability, which is our lower specification limit. This represents a long-term predictive capability index for
Ppk = 1.68.
When To Use Weibull
Weibull failure analysis can be a powerful tool to build similar predictive simulations of fatigue life with Shape and Scale functions from historical testing. It can also determine reliability analysis from durability or accelerated sample testing and can be done with very few samples. In addition, Hazard and Survival plots can be generated to visualize statistical failure data.
If the failure data does not fit a standard 2-parameter Weibull particularly well, there is a 3-parameter Weibull that can be utilized when the data points do not fall on a straight probability line but curve up or down (Figure 8).

There are two main points to consider in deciding to use the 3-parameter Weibull distribution. First of all, can a value of a location parameter (X = Time or Stress, etc.) that is not zero work? It can as long as the location parameter is less than the first failure data. Therefore, if your probability plot shows curvature and the AD statistic is around 0.50 (smaller is better), a 3-parameter Weibull can be a great option to fit your data more exactly.
Conclusion
Weibull analysis can be simple and complex. It is the only function that can handle censored data. These are situations where not all of the samples have failed or failure has occurred but the time or unit of failure is known only within a range. The exact value is uncertain, yet an estimation of failure life can be made. This is often the case with warranty data. Another censoring case is a test that is stopped at a predetermined time; some samples have failed, and others have not. In large sample sizes and in censoring scenarios, the probability percentiles are best calculated by the maximum-likelihood estimation rather than the least-squares method. Maximizing the likelihood function determines the parameters that are most likely to correlate to the observed data. However, the examples in this paper use least-squares because the AD statistic was 8.0 percent smaller than with the maximum-likelihood method for the data used. Maximum-likelihood is usually best, but all statistics need to be evaluated to select the appropriate choice.













